청크지향처리 즉, ChunkOrientedTasklet를 이용한 스프링 배치에서 아이템 수집의 시작이자 스프링 배치를 다양하게 또는 간편하게 적용할 수 있게 해주는 ItemReader에 대해 알아보도록 하겠다.
ItemReader는 청크 방식일때만 적용이 가능하다. 스프링 배치에서 기본적으로 제공하는 ItemReader의 구현체들은 굉장히 많은데 대표적으로 PaingItemReader, CursorItemReader, ItemReaderAdapter 등이 있다.
ChunkOrientedTasklet의 ItemReader 동작
Chunk지향 처리의 배치가 실행하게 되면 chunkProvider에 의해 read, chunkProcessor 에 의해 process, write 작업이 순서대로 이루어지게 되는데
chunkProvider.provide(contribution)가 아이템을 read 하는 과정, chunkProcessor.process(contribution, inputs)가 아이템을 process, write하는 과정으로 나누어져 있다.
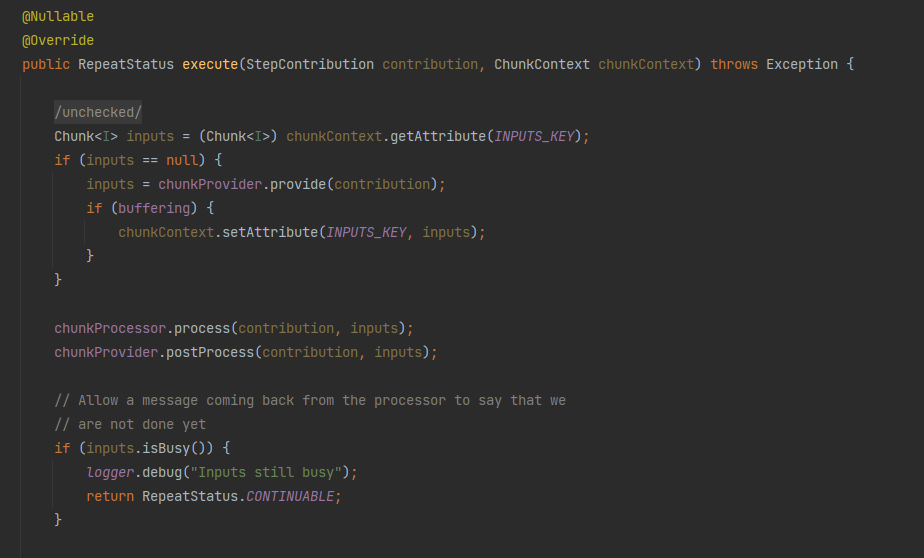
provide 메소드를 실행하게 되면 SimpleChunkProvider를 통해 itemReader의 read() 실행으로 Item을 가져오게 된다.

이때 ItemReader의 어떤 구현체를 사용하느냐에 따라 아이템을 가져오는 방식 조금 달라지게 되는데 대표적인 예가 AbstractItemCountingItemStreamItemReader 추상클래스를 이용한 ItemReader들이다.
해당 추상클래스를 구현한 클래스들은 모두 read() 메소드를 실행 시 doRead()의 추가 작업을 통해 아이템을 가져오게 되는데 doRead()는 List 단위로 아이템을 가져온 후 한 개씩 processor로 넘겨주는 역할을 하고 있다.

멀티스레드 환경에선 ItemCounting 기능만으로는 데이터 중복 수집이 발생하기 때문에 thread-safe한 ItemReader를 적용해야 한다. 대표적인 예시로 AbstractPagingItemReader가 있으며 해당 클래스는 synchronized가 적용된 doRead()메소드를 이용하여 데이터를 한 개씩 Processor로 넘기는데 데이터가 없다면 doReadPage() 메소드를 이용해 results 리스트에 데이터를 추가해주는 구조이다.
AbstractPagingItemReader를 상속받은 후 doReadPage() 메소드를 구현해 원하는 데이터 리스트를 results에 추가해줌으로써 멀티쓰레드로부터 안전한 ItemReader를 구현할 수 있다.

다양한 ItemReader의 구현 방법
배치 기능을 사용하는 대부분의 이유가 주기적으로 대용량 데이터를 가공하기 위해서 적용하는 경우일텐데 이를 위해 스프링 배치에서는 데이터베이스에서 데이터를 가져오는 ItemReader 몇 개를 기본 제공하고 있다. 그 중 몇 개만 간단하게 설명하겠다.
JdbcPagingItemReader
thread-safe한 Paging 방식의 ItemReader이다.
public JdbcPagingItemReader<Employee> jdbcPagingReader() throws Exception {
JdbcPagingItemReader<Employee> jdbcPagingReader = new JdbcPagingItemReaderBuilder<Employee>()
.name("jdbcPagingReader")
.pageSize(3) //페이지의 사이즈를 설정해준다. (쿼리 당 요청할 레코드 수)
.fetchSize(20)
.dataSource(dataSource)
.beanRowMapper(Employee.class) //객체 클래스를 넣으면 자동으로 DB 데이터가 객체에 맵핑됨.
.maxItemCount(10)//한번에 조회할 최대 item 수 설정
.currentItemCount(0)//조회 Item의 시작 지점 설정
.queryProvider(createQueryProvider())
.build();
jdbcPagingReader.afterPropertiesSet();
return jdbcPagingReader;
}JdbcCursorItemReader
not thread-safe한 Cursor방식의 ItemReader이다.
public JdbcCursorItemReader<Employee> jdbcCursorReader() {
return new JdbcCursorItemReaderBuilder<Employee>()
.name("jdbcCursorReader")
.fetchSize(20)
.dataSource(dataSource)
.beanRowMapper(Employee.class)
.sql("select empno, ename, job, hiredate, sal, deptno from emp")
.maxItemCount(20)
.currentItemCount(0)
.build();
}JpaPagingItemReader
thread-safe한 Paging 방식의 ItemReader이다.
public JpaPagingItemReader<Employee> jpaPagingReader() {
return new JpaPagingItemReaderBuilder<Employee>()
.name("jpaPagingReader")
.entityManagerFactory(emf)
.queryString("select e.empNo, e.eName, e.job, e.hireDate, e.sal, e.deptNo from Employee e")
.pageSize(5)
.build();
}JpaCursorItemReader
not thread-safe한 Cursor방식의 ItemReader이다.
public JpaCursorItemReader<Employee> jpaCursorReader() {
return new JpaCursorItemReaderBuilder<Employee>()
.name("jpaCursorItemReader")
.entityManagerFactory(emf)
.queryString("select e.empNo, e.eName, e.job, e.hireDate, e.sal, e.deptNo from Employee e")
.currentItemCount(0) //조회 item의 시작지점
.maxItemCount(100) //조회할 최대 item 수
.build();
}
paging 방식을 이용한 CustomItemReader
AbstractItemCountingItemStreamItemReader를 상속받아 직접 구현한 Custom Item Reader로 doRead에 synchronized를 이용해 thread-safe 할 수 있도록 적용해 주었다.
public class CustomItemReader<T> extends AbstractItemCountingItemStreamItemReader<T> {
private volatile int page = 1;
private volatile int row = 100;
private volatile boolean initialized = false;
protected volatile List<T> results = new LinkedList<>();
protected final Object lock = new Object();
public CustomItemReader() {
setSaveState(false);
setName(ClassUtils.getShortName(this.getClass()));
}
@Override
protected T doRead() throws Exception {
synchronized (lock) {
//results 값이 없어도 종료되면 안됨 오직 null일 때만 종료
if (results == null) {
return null;
} else if (results.size() > 0) {
return results.remove(0);
} else {
doReadPage();
page++;
return doRead();
}
}
}
public void doReadPage() {
List<Employee> employees = new ArrayList<>();
if(page < 5){
Employee employee1 = new Employee();
employee1.setEmpNo(page);
employees.add(employee1);
Employee employee2 = new Employee();
employee1.setEmpNo(page);
employees.add(employee2);
Employee employee3 = new Employee();
employee1.setEmpNo(page);
employees.add(employee3);
}
if(employees.isEmpty()){
results = null;
}else{
results.addAll((Collection<? extends T>) employees);
}
}
@Override
protected void doOpen() throws Exception {
Assert.state(!initialized, "Cannot open an already opened ItemReader, call close first");
initialized = true;
}
@Override
protected void doClose() throws Exception {
synchronized (lock) {
initialized = false;
results = null;
}
}
}
전체 코드
@Configuration
@EnableBatchProcessing
public class ExampleItemReaderJobConfiguration {
private final JobBuilderFactory jobBuilderFactory;
private final StepBuilderFactory stepBuilderFactory;
@Resource(name = "hikari_oracle")
private DataSource dataSource;
@Autowired
private EntityManagerFactory emf;
public ExampleItemReaderJobConfiguration(JobBuilderFactory jobBuilderFactory, StepBuilderFactory stepBuilderFactory) {
this.jobBuilderFactory = jobBuilderFactory;
this.stepBuilderFactory = stepBuilderFactory;
}
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setThreadNamePrefix("ThreadPool");
executor.setMaxPoolSize(10);
executor.setCorePoolSize(5);
executor.setAllowCoreThreadTimeOut(true);
executor.initialize();
return executor;
}
@Bean
public Job itemReaderJob() throws Exception {
return jobBuilderFactory.get("itemReaderJob")
.incrementer(new RunIdIncrementer())
.preventRestart() //중단 시 재시작 방지
.start(jdbcPagingStep())
.next(jdbcCursorStep())
.next(jpaPagingStep())
.next(jpaCursorStep())
.next(customStep())
.build();
}
public Step jdbcPagingStep() throws Exception {
return stepBuilderFactory.get("jdbcPagingStep")
.chunk(1)
.reader(jdbcPagingReader())
.writer(writer())
.build();
}
public Step jdbcCursorStep() throws Exception {
return stepBuilderFactory.get("jdbcCursorStep")
.chunk(100)
.reader(jdbcCursorReader())
.writer(writer())
.build();
}
public Step jpaPagingStep() throws Exception {
return stepBuilderFactory.get("jpaPagingStep")
.chunk(100)
.reader(jpaPagingReader())
.writer(writer())
.build();
}
public Step jpaCursorStep() throws Exception {
return stepBuilderFactory.get("jpaCursorStep")
.chunk(100)
.reader(jpaCursorReader())
.writer(writer())
.build();
}
public Step customStep() throws Exception {
return stepBuilderFactory.get("customStep")
.chunk(100)
.reader(customReader())
.writer(writer())
.build();
}
public JdbcPagingItemReader<Employee> jdbcPagingReader() throws Exception {
JdbcPagingItemReader<Employee> jdbcPagingReader = new JdbcPagingItemReaderBuilder<Employee>()
.name("jdbcPagingReader")
.pageSize(3) //페이지의 사이즈를 설정해준다. (쿼리 당 요청할 레코드 수)
.fetchSize(20)
.dataSource(dataSource)
.beanRowMapper(Employee.class) //객체 클래스를 넣으면 자동으로 DB 데이터가 객체에 맵핑됨.
.maxItemCount(10)//한번에 조회할 최대 item 수 설정
.currentItemCount(0)//조회 Item의 시작 지점 설정
.queryProvider(createQueryProvider())
.build();
jdbcPagingReader.afterPropertiesSet();
return jdbcPagingReader;
}
public JdbcCursorItemReader<Employee> jdbcCursorReader() {
return new JdbcCursorItemReaderBuilder<Employee>()
.name("jdbcCursorReader")
.fetchSize(20)
.dataSource(dataSource)
.beanRowMapper(Employee.class)
.sql("select empno, ename, job, hiredate, sal, deptno from emp")
.maxItemCount(20)
.currentItemCount(0)
.build();
}
public JpaPagingItemReader<Employee> jpaPagingReader() {
return new JpaPagingItemReaderBuilder<Employee>()
.name("jpaPagingReader")
.entityManagerFactory(emf)
.queryString("select e.empNo, e.eName, e.job, e.hireDate, e.sal, e.deptNo from Employee e")
.pageSize(5)
.build();
}
public JpaCursorItemReader<Employee> jpaCursorReader() {
return new JpaCursorItemReaderBuilder<Employee>()
.name("jpaCursorItemReader")
.entityManagerFactory(emf)
.queryString("select e.empNo, e.eName, e.job, e.hireDate, e.sal, e.deptNo from Employee e")
.currentItemCount(0) //조회 item의 시작지점
.maxItemCount(100) //조회할 최대 item 수
.build();
}
public CustomItemReader<Employee> customReader() {
return new CustomItemReader<Employee>();
}
public PagingQueryProvider createQueryProvider() throws Exception {
SqlPagingQueryProviderFactoryBean queryProviderFactoryBean = new SqlPagingQueryProviderFactoryBean();
queryProviderFactoryBean.setDataSource(dataSource);
queryProviderFactoryBean.setSelectClause("empno, ename, job, hiredate, sal, deptno");
queryProviderFactoryBean.setFromClause("from emp");
Map<String, Order> sortKey = new HashMap<>();
sortKey.put("empno", Order.ASCENDING);
queryProviderFactoryBean.setSortKeys(sortKey);
return queryProviderFactoryBean.getObject();
}
public ItemWriter<? super Object> writer() {
return new JbgroundWriter<>();
}
}
전체 소스 보기
'Java' 카테고리의 다른 글
| [Thread] 뮤텍스, 세마포어, 모니터의 스레드 동기화와 구현 예제 (0) | 2023.06.20 |
|---|---|
| [Spring Batch] 한 개의 Step에 여러 개의 Processor의 다중 적용이 필요할 경우(CompositeProcessor, 예제 포함) (0) | 2023.01.18 |
| [Thymeleaf] 타임리프 유틸 함수 - #strings, #arrays 등등 (0) | 2022.10.05 |
| [Spring Batch] #4 스프링 배치 Step 과 Tasklet (0) | 2022.09.27 |
| [Spring Batch] #3 스프링배치 동작 방식 - 기본 (0) | 2022.09.20 |


